TF-IDF: Term Frequency-Inverse Document Frequency
TF-IDF, which stands for Term Frequency-Inverse Document Frequency, is a statistical measure used to evaluate the importance of a word to a document in a collection or corpus. This measure helps in information retrieval and text mining by adjusting the frequency of words by how often they appear across multiple documents. In essence, TF-IDF increases proportionally with the number of times a word appears in a document and is offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general.
- Term Frequency (TF): This measures how frequently a term occurs in a document. There are several ways to calculate term frequency, with the simplest being the raw count of a term in a document. The term frequency is often normalized to prevent a bias towards longer documents (which may have a higher term count regardless of the actual importance of a word in the document).
- Inverse Document Frequency (IDF): This measures how important a term is within the whole corpus. The more common a word is, the lower its IDF.
Code Implementation:
tf(t, d) # Times term t_i occurs in document d_i / Total number of words in document d_i
df(t) # Documents containing term t
idf(t, D) = log(N / (df(t) + 1)) + 1
tf-idf(t, d, D) = tf(t, d) * idf(t, D)
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
corpus = [
"the quick brown fox jumped over the lazy dog",
"the dog jumped over the moon",
"the quick brown fox",
]
tr_idf_model = TfidfVectorizer()
tf_idf_vector = tr_idf_model.fit_transform(corpus)
tf_idf_array = tf_idf_vector.toarray()
# Print TF-IDF Vectors
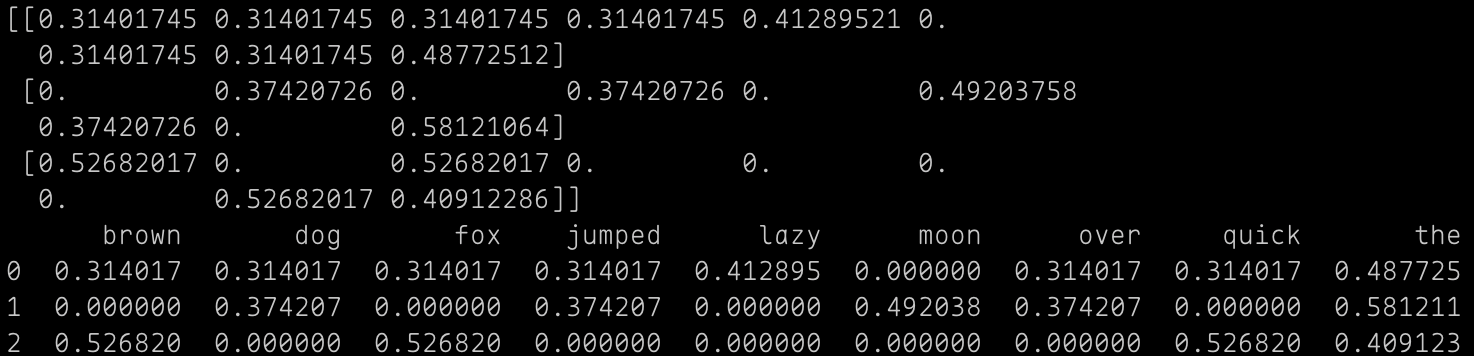
print(tf_idf_array)
# Exhibit TF-IDF Vectors
words_set = tr_idf_model.get_feature_names_out()
df_tf_idf = pd.DataFrame(tf_idf_array, columns = words_set)
pd.set_option('display.max_rows', False)
print(df_tf_idf)
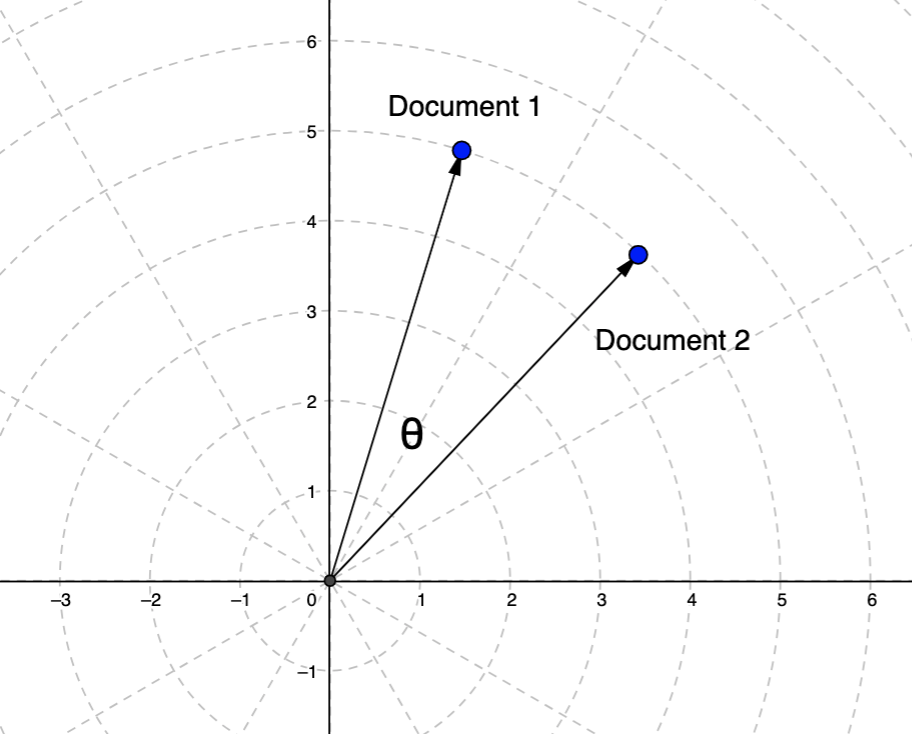
Cosine Similarity
Cosine similarity is a measure used to determine how similar two vectors are irrespective of their size. Commonly used in text analysis and other multidimensional data spaces, it is particularly useful in high-dimensional positive space where the angle between vectors is a good indication of their similarity.
Code Implementation:
import numpy as np
def cosine_similarity(A, B):
dot_product = np.dot(A, B)
norm_A = np.linalg.norm(A)
norm_B = np.linalg.norm(B)
return dot_product / (norm_A * norm_B)
# Example TF-IDF Vectors
vector_A = np.array([1, 2, 3])
vector_B = np.array([4, 5, 6])
# Compute cosine similarity
similarity = cosine_similarity(vector_A, vector_B)
print(f"Cosine Similarity: {similarity}")