为了捕获、过滤和分析Linux服务器上的流量,可以使用 Python 和 tcpdump 结合 libpcap 库来完成这个任务。
1. 安装依赖
首先,需要确保系统上安装了 tcpdump 和 libpcap。在大多数 Linux 发行版上,可以使用包管理器安装它们:
sudo apt install tcpdump libpcap-dev
然后,需要安装 Python 的 scapy 库,它可以帮助我们解析 pcap 文件:
pip install scapy
2. 使用 tcpdump 捕获数据包
接着,通过 tcpdump 命令行工具来捕获网络流量并将其保存到一个 pcap 文件中。例如,以下命令捕获所有流量并保存到 capture.pcap 文件中:
sudo tcpdump -i eth0 -w capture.pcap
3. 使用 Python 解析 pcap 文件
然后,使用 scapy 库解析 pcap 文件的示例 Python 脚本:
from scapy.all import rdpcap
# 读取 pcap 文件
packets = rdpcap('capture.pcap')
# 打印每个数据包的摘要信息
for packet in packets:
print(packet.summary())
4. 结合所有步骤
编写一个 Python 脚本来自动化整个过程,包括调用 tcpdump 来捕获数据包,然后使用 scapy 解析捕获的文件。以下是一个完整的示例:
目标是筛选出与 Chrome 浏览器相关的 IP 数据包和 TCP 数据包,并打印它们的摘要信息。Chrome 浏览器使用 HTTP(端口 80)和 HTTPS(端口 443)协议来传输数据,我们可以基于这些端口进行筛选。
import subprocess
from scapy.all import rdpcap, IP, TCP
# 捕获特定网卡(default=eth0)的数据包并保存到 capture.pcap 文件
def capture_packets(interface="eth0", output="capture.pcap", duration=10):
subprocess.run(
[
"sudo", "tcpdump",
"-i", interface,
"-w", output,
"-G", str(duration),
"-W", "1",
]
)
# 解析 pcap 文件并筛选出与 Chrome 浏览器相关的数据包
def parse_pcap(file):
packets = rdpcap(file)
# Chrome 浏览器常用的端口
chrome_ports = [80, 443]
# 筛选 Chrome 浏览器的 IP 数据包和 TCP 数据包
chrome_packets = [
packet
for packet in packets
if (
IP in packet
and TCP in packet
and (packet[TCP].sport in chrome_ports or packet[TCP].dport in chrome_ports)
)
]
# 打印每个数据包的摘要信息
for packet in chrome_packets:
print(packet.summary())
if __name__ == "__main__":
# 捕获流量 10 秒
capture_packets(duration=10)
# 解析并打印捕获的与 Chrome 浏览器相关的数据包
parse_pcap("capture.pcap")
注意事项
- 权限:
tcpdump需要超级用户权限才能捕获网络流量,因此需要以sudo运行脚本或命令。 - 性能:捕获和处理大量数据包可能会对系统性能产生影响,特别是在高流量环境中。
- 安全性:确保有权限在网络上捕获数据包,并且不要在未经授权的情况下监控他人的网络流量。
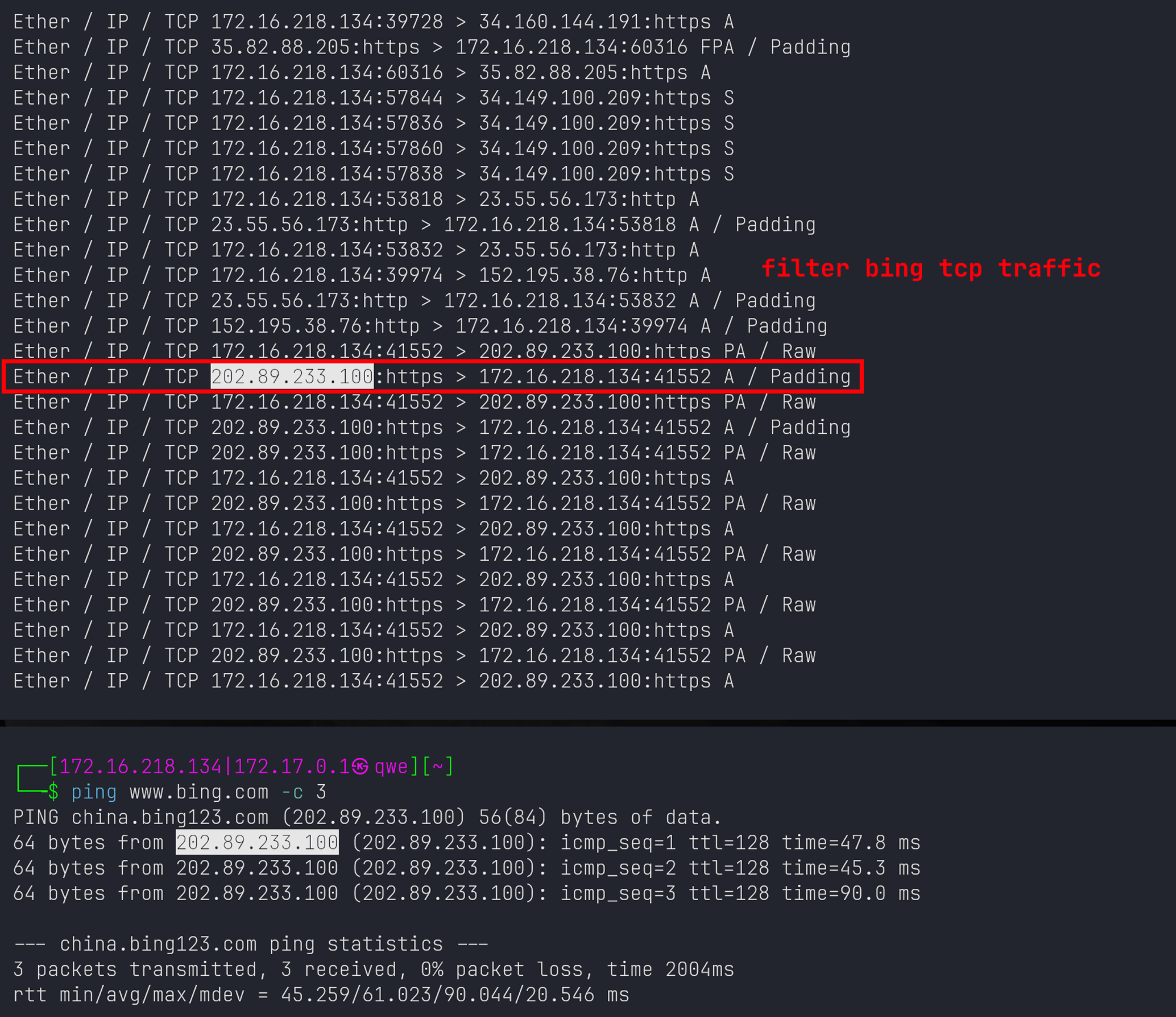
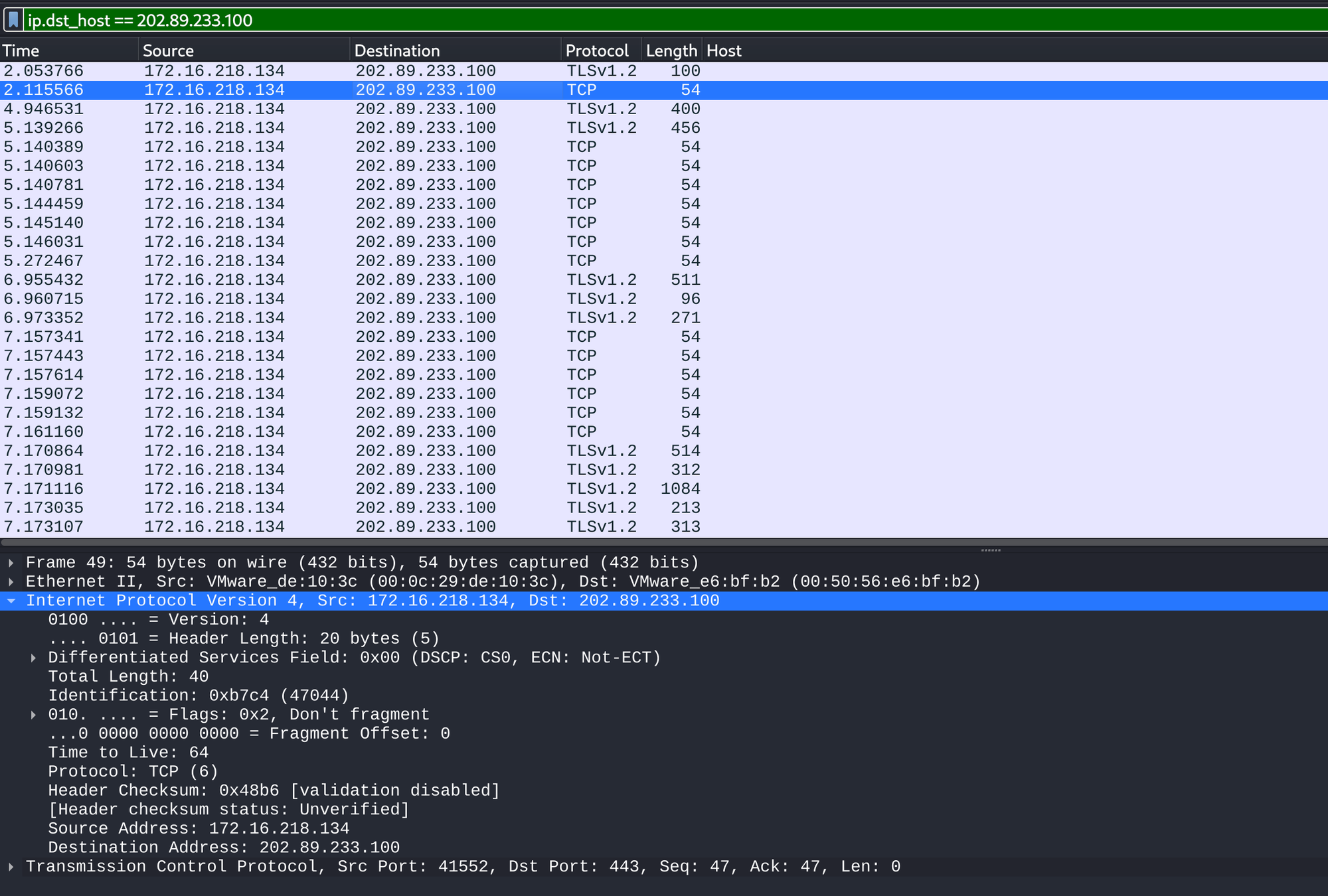
Screenshots
下图显示了脚本运行的截图和Wireshark分析捕获的pcap文件的过滤截图,显示脚本的有效性。后续更多的功能改动为:设置一些更为复杂的过滤规则以获取重要的流量特征;除了打印每个数据包的摘要信息,可以输出更丰富的日志来记录流量特征。