词嵌入(Word Embedding) 是一种将语言词语转化为数值形式的技术,目的是让计算机能够理解和处理自然语言。在这种表示方法中,每个词被映射到一个固定长度的向量(通常由浮点数构成)。这些向量捕捉了词语之间的语义关系,如相似性和共现关系,使得相似的词语在向量空间中彼此接近。词嵌入是通过机器学习模型从大量文本数据中自动学习得到的,常见的模型包括Word2Vec、GloVe等。
One Hot Vector
One-hot编码常用于将词语转化为向量,每个词语都表示为一个很长的向量,该向量中只有一个元素是1,其余都是0。这种方式的向量维度通常等于词汇表的大小,其中每个维度代表词汇表中的一个词。这种方法的主要缺点是无法表达词与词之间的相似性,且向量维度通常非常高,容易导致维度过高。
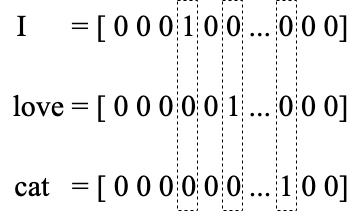
Bag of Words
Bag of Words(词袋模型) 是一种简单而强大的自然语言处理技术,用于文本特征提取。在这种模型中,文本(如句子或文档)被表示为词语的集合,不考虑语法和词序,只考虑词频(每个词出现的次数)。这种表示形式通常用于文本分类和文档相似性比较。

TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency) 是一种用于信息检索和文本挖掘的统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要性。原理是:一个词语的重要性随着它在文档中出现的频率成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
Word2Vec, FastText
Efficient Estimation of Word Representations in Vector Space
Distributed Representations of Words and Phrases and their Compositionality
Word2Vec 将词语转换为数值形式的密集向量,这些向量捕捉到了词语间的语义和语法关系。Word2Vec 的核心优势在于其能够识别出相似词语之间的模式,使得在向量空间中距离相近的词具有相似的含义。
FastText 是Word2Vec的扩展,同样支持CBOW和Skip-gram模型。其创新之处在于不仅仅学习词的嵌入,还学习词内部的子字符串(n-gram)的嵌入,这使得模型能够更好地处理未见过的词和复杂的语言现象,如词形变化。
- CBOW (Continuous Bag of Words):这个模型预测目标词基于其上下文。具体来说,模型通过查看一个窗口中的上下文词来预测中间的词。这种方法更快,并且对于频繁出现的词效果更好。
- Skip-gram:与 CBOW 相反,Skip-gram 模型通过一个目标词来预测周围的上下文词。这种方法擅长处理大量数据,并且能够捕捉到更稀疏的数据关系。