Introduction
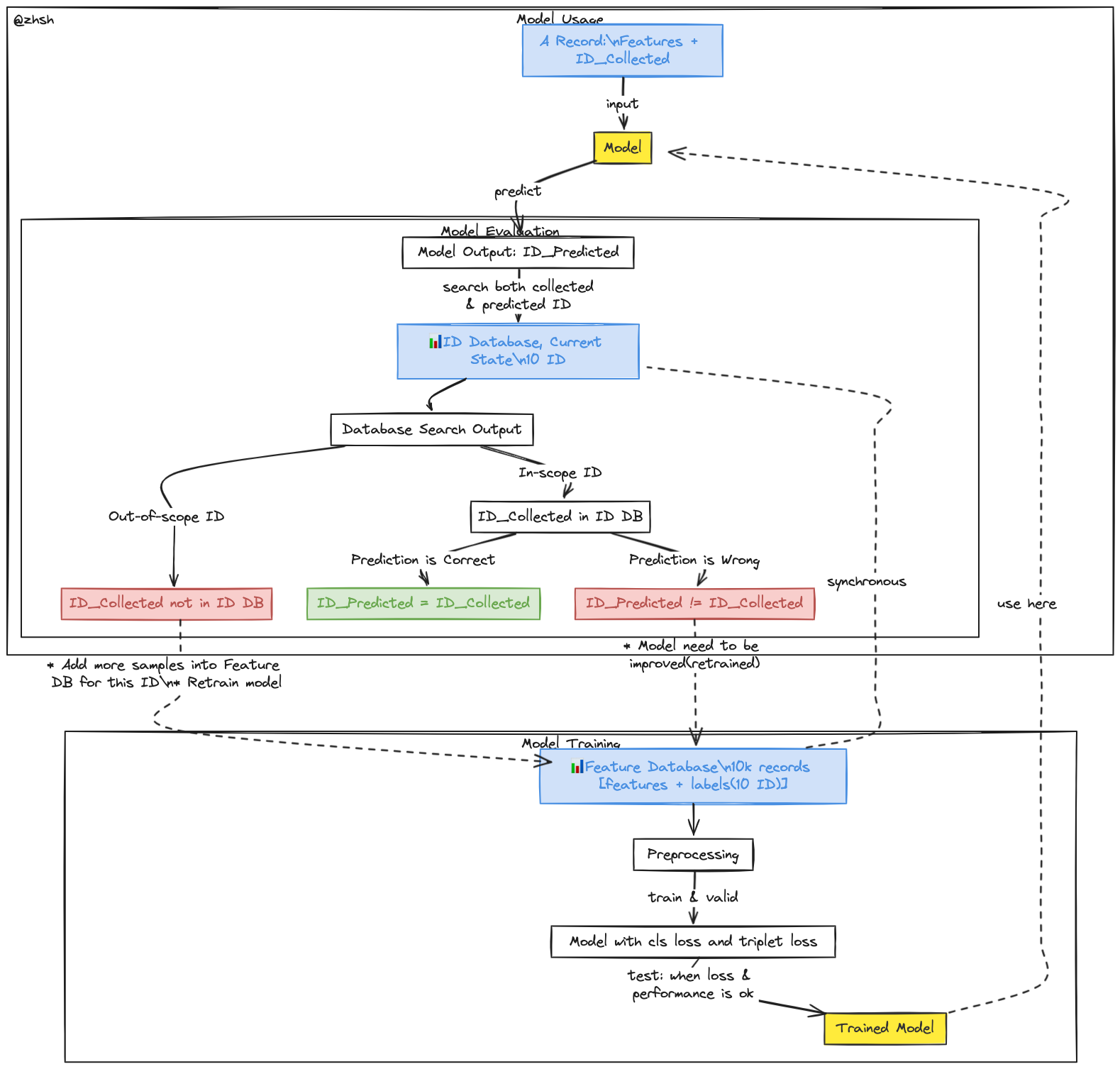
The diagram depicts a comprehensive design for an ID detection model, encompassing stages from data preprocessing and model training to model usage and evaluation. This design is structured into two primary subgraphs: "Model Training" and "Model Usage," which also includes "Model Evaluation." The following sections detail each component, followed by an analysis of the design's advantages and disadvantages.
Model Training
The "Model Training" subgraph outlines the steps involved in preparing and training the ID detection model:
- Feature Database: This repository initially contains 10,000 records, each comprising features and labels corresponding to 10 different IDs.
- Preprocessing: Data preprocessing ensures the data is in a suitable format for training. This stage includes operations such as normalization, augmentation, and dataset splitting into training and validation sets.
- Model Training: The preprocessed data is used to train the model utilizing a combination of classification loss and triplet loss, which aids in learning to classify IDs and distinguish between different IDs effectively.
- Trained Model: Upon achieving satisfactory loss and performance metrics during testing, the model is considered trained and ready for deployment.
The trained model is subsequently employed in the "Model Usage" subgraph.
Model Usage
The "Model Usage" subgraph illustrates the process by which the trained model makes predictions:
- Input Record: A new record, containing features and an ID collected in real-time, is input into the deployed model.
- Model Output: The model predicts an ID based on the input features.
- Database Interaction: The predicted ID and the collected ID are verified against the current state of the ID database.
Model Evaluation
Within the "Model Usage" subgraph, the "Model Evaluation" process is critical for assessing the model's predictions:
- Database Search Output: This step involves searching the ID database for both the collected and predicted IDs.
- Out-of-Scope ID: If the collected ID is not found in the ID database, this implies the model encountered an unknown ID, necessitating the addition of more samples for this ID into the feature database and retraining the model.
- In-Scope ID: If the collected ID is found in the database, further evaluation of the prediction occurs:
- Correct Prediction: If the predicted ID matches the collected ID, the prediction is deemed correct.
- Incorrect Prediction: If the predicted ID does not match the collected ID, the model requires improvement and retraining.
Advantages
- Comprehensive Training Process: The design incorporates both classification and triplet loss, ensuring robust learning and accurate ID differentiation.
- Continuous Improvement: The feedback loop from evaluation to retraining allows for continuous model refinement, accommodating new IDs and improving accuracy over time.
- Scalability: The structured preprocessing and training pipeline can handle large datasets, making it scalable.
- Real-Time Adaptation: The system’s capability to update the feature database and retrain the model with new IDs ensures it remains relevant and accurate in dynamic environments.
Disadvantages
- Complexity: The multi-step process involving preprocessing, training, evaluation, and retraining can be complex and resource-intensive, requiring substantial computational power and time.
- Dependency on Data Quality: The model’s performance heavily relies on the quality and diversity of the initial feature database. Poor-quality data can lead to inaccurate predictions and frequent retraining.
- Latency in Adaptation: While the system can adapt to new IDs, there may be delays in updating the feature database and retraining the model, affecting real-time performance.
- Maintenance Overhead: The continuous need to monitor model performance, update databases, and retrain the model imposes a significant maintenance burden on system administrators.
Designing a Model for Large-Scale ID Identification
To extend this model to handle a significantly larger number of IDs, such as 10 million, specific strategies and design considerations must be implemented:
-
Hierarchical Classification: Employ a hierarchical classification approach wherein IDs are grouped into clusters or categories. The model first predicts the category and then the specific ID within that category, thereby reducing the complexity of the classification task.
-
Embedding Representations: Utilize embedding representations where IDs are mapped to a continuous vector space. Techniques such as metric learning ensure that similar IDs have closer embeddings, allowing for efficient nearest-neighbor searches in a high-dimensional space.
-
Scalable Databases: Implement scalable database solutions capable of handling large volumes of data. Technologies like distributed databases (e.g., Cassandra, HBase) can store and manage millions of ID records efficiently.
-
Incremental Learning: Develop an incremental learning framework where the model can be updated with new IDs without necessitating a complete retraining from scratch. This involves techniques such as online learning and model fine-tuning.
-
Efficient Indexing: Implement efficient indexing techniques to manage large-scale databases. Methods like Locality-Sensitive Hashing (LSH) or Approximate Nearest Neighbor (ANN) search can significantly speed up the retrieval process in high-dimensional spaces.
-
Distributed Computing: Leverage distributed computing frameworks such as Apache Spark or TensorFlow Distributed to parallelize the processing and training tasks. This approach can handle the vast computational load required for managing and training on datasets with millions of IDs.
-
Model Compression: Apply model compression techniques, such as quantization and pruning, to reduce the model size and improve inference speed without significantly compromising accuracy. This is particularly important for deploying models in resource-constrained environments.
-
Federated Learning: Use federated learning to enable multiple decentralized systems to collaboratively train the model while keeping the data localized. This not only addresses privacy concerns but also allows the model to learn from a diverse set of IDs spread across different environments.
-
Continuous Monitoring and Evaluation: Establish a robust monitoring system to continuously evaluate the model’s performance. Implementing automated retraining pipelines that trigger based on performance degradation or the introduction of new IDs ensures the model remains accurate and up-to-date.
Conclusion
The proposed ID detection model design addresses the fundamental aspects of preprocessing, training, usage, and evaluation, providing a solid foundation for accurate ID detection. However, scaling this model to handle a significantly larger number of IDs, such as 10 million, requires additional strategies. These include hierarchical classification, embedding representations, scalable databases, incremental learning, efficient indexing, distributed computing, model compression, federated learning, and continuous monitoring.
By integrating these advanced techniques, the model can maintain its accuracy and efficiency while scaling to accommodate a vast number of IDs. This ensures the system remains robust, adaptable, and capable of meeting the demands of large-scale identification tasks.
References
- Bengio, Y., Courville, A., & Vincent, P. (2013). Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798-1828.
- Dean, J., & Ghemawat, S. (2008). MapReduce: Simplified Data Processing on Large Clusters. Communications of the ACM, 51(1), 107-113.
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531.
- McMahan, H. B., Moore, E., Ramage, D., & Hampson, S. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, 54, 1273-1282.
These references provide a deeper understanding of the techniques and methodologies discussed, offering further insights into effective ID detection model design and large-scale implementation strategies.